In this series, I plan to build intuition for machine learning topics leading up to modern neural networks, below is the plan for the series and links to completed posts:
- Gradient Descent
- Logistic Regression for Classification
- Two Layer Neural Network
- Gradients Over Many Layers
- Modern Deep Learning Frameworks
Introduction
Gradient descent is a simple and intuitive optimization method that is common across a large space of problems ranging from simple linear regression to neural networks.
With this, we can optimize against a given function and determine parameters that give us the best performance. By the end of this post, you should have a good idea on how this optimizer works and how to apply it to new problems.
Prior Knowledge
There are a few concepts that you should know before coming into this post, in general I try to explain everything clearly but it helps if you have prior exposure to these concepts.
- NumPy: NumPy is used as the data storage and computation backbone. If you’re not familiar with NumPy matrices take a look at this resource.
- Calculus: We rely on derivatives, in particular, partial derivatives!
Gradients
Before we step into how we use the gradient to help in our optimization problem, let’s first build some understanding around the gradient. For those who are unfamiliar with partial derivatives or want a refresher you can take a look at the aside below.
Gradient Intuition
The gradient of a function is actually quite a simple concept but can be so powerful when used correctly. The way to think about the gradient intuitively is that it’s a vector that points in the direction of greatest increase for your given function .
It’s a vector in the sense that it has the direction where max increase happens as well as the magnitude of the increase. The components of the vector lie in the space of the function so if the function takes one input the gradient is only one value and direction.
Gradient Definition
Formally, we can define the gradient in terms of partial derivatives such that we could actually compute a gradient. Consider a function that depends on 3 input variables , , and . The gradient is a vector of partial derivatives.
If you’re standing at a point and compute the gradient at that point, you’d be getting the vector pointing in the direction from where you are such that you would climb the fastest. A clearer way to show this is that we evaluate each partial derivative at our point.
Don’t be worried about the math for now, I just want you to take the intuition and roll with it for now. If you plan to implement this from scratch you’ll need to actually evaluate this but for now just know it points to where we climb fastest given a starting point!
Gradient Descent
Now that we have an understanding of how to compute gradients and what information they give us, let’s use it to optimize our problems through gradient descent.
Descent Intuition
Imagine you’re stranded on a massive hill, surrounded by thick fog where you can only see a few feet in any direction. Your goal is to get down to the bottom, but the limited visibility makes it impossible to chart a full path from where you are.
So, you make a simple decision: take a small step in the direction that slopes downward the most from where you’re currently standing. Then you repeat. Each time you move, the fog shifts just enough to reveal new terrain, allowing you to reassess and adjust your direction. Over time, by continuously stepping downhill in the steepest local direction, you’ll eventually find yourself in a valley or if you’re lucky, at the very bottom.
That’s essentially what gradient descent is. In the next section, we’ll take this intuition and connect it to the math behind the algorithm.
Descent Definition
Let’s formally define gradient descent and associate our example back to the components of it. In the simplest form, gradient descent is repeatedly computing the following equation.
- is the function we’re minimizing with gradient descent, it’s the height of the hill
- is the set of variables for , it’s the and position on the hill
- is the gradient of evaluated at , the direction we move on the hill
- is a scalar to decrease how big of a step we take, often called learning rate
Local vs Global Minima
Another aspect of the problem we should connect is the idea of an intermediate valley in the hill landscape versus true bottom. This difference is called local and global minimas.
With gradient descent there is a problem in which depending on the loss function we are not guaranteed that we’ll land at the global minima, the lowest point over the entire landscape. Let’s consider some simple cases to see why this is can be a problem.
Convex Function
In a convex function, there is only one minima and that implies it’s the global minima. A simple convex function is a parabola so when we execute gradient descent over this function we always land at the global minimum no matter where we start.
In the video, the blue represents the partial derivative so with descent we expect to go opposite this direction as we change the value of x with the negative of the gradient.
Multiple Minima Function
Let’s consider a function where there are multiple minimas, in particular we have two equivalent global minimas and one local minima in the center. When we start gradient descent at various points we see that we don’t always get to the global minima.
Resolutions
In practice, we don’t know what the loss landscape looks like for large models. There is research on variations of gradient descent to help mitigate these problems as well as improve training speed and overall performance. The go-to right now is the Adam optimizer which varies automatically based on patterns observed in prior iterations.
Just to give you an idea what these more complicated landscapes look like, consider this work done to try to visualize them! Mind you, in most applications the number of inputs variables is larger than we can visualize so this is an attempt at visualizing.

Hill Descent
Before we step into linear regression, let’s try to emulate the hill descent.
Surface and Gradient Equation
For our primary function , we need to model the height of where we would be on the hill at a position which simply means we need something of the form . For this example I opted to use simple sin waves over the multiple variables.
Why is height the right equation to minimize? Well consider that whatever function we model we will end up minimizing its value so we want that behavior to match our goals. In this case, we are trying to get to the base of the hill which means we want to minimize our height. Let’s go ahead and compute the corresponding partial derivatives.
What we have now are the equations to know how high we are based on our position and the associated gradient for those positions to know which direction we should follow!
Visualizing the Descent
Let’s try to visualize what is going on and see if we can draw some conclusions to help our understanding. First, let’s initialize some points randomly on these hills and execute gradient descent on each of them to see where they end up.
Descent Animation
Let’s go ahead and take a look at the hills example realized! What you can see is a 3D view and a top down view of the paths taken by each of the points.
They all reach minimums which is what we expect! Something to note is that you can see that depending on where the points start they have a destined minimum they’ll end up in, in other landscapes this may mean that a point will terminate at a local not a global minima!
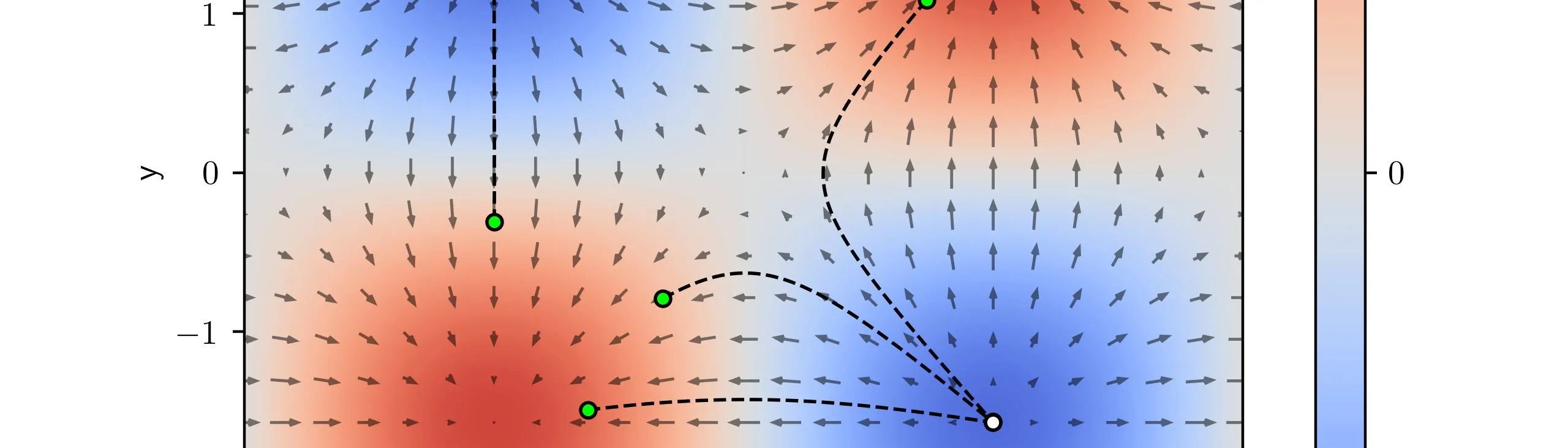
Gradient Field
We can evaluate the gradient at a grid of points across the space we’re in. We know that the gradient produces a vector over and so we can plot the gradient as an arrow pointing in the gradient direction. This grid of arrows is called a gradient vector field.
Plotting the paths from before over the vector field we can see that the path the points take almost exactly follows the opposite of the gradient which makes sense! The gradient points in the direction of greatest increase so when we descend we follow the opposite of the gradient to achieve the path of greatest decrease. We could just as easily follow the gradient if we wanted to maximize a function called gradient ascent but this isn’t nearly as common.
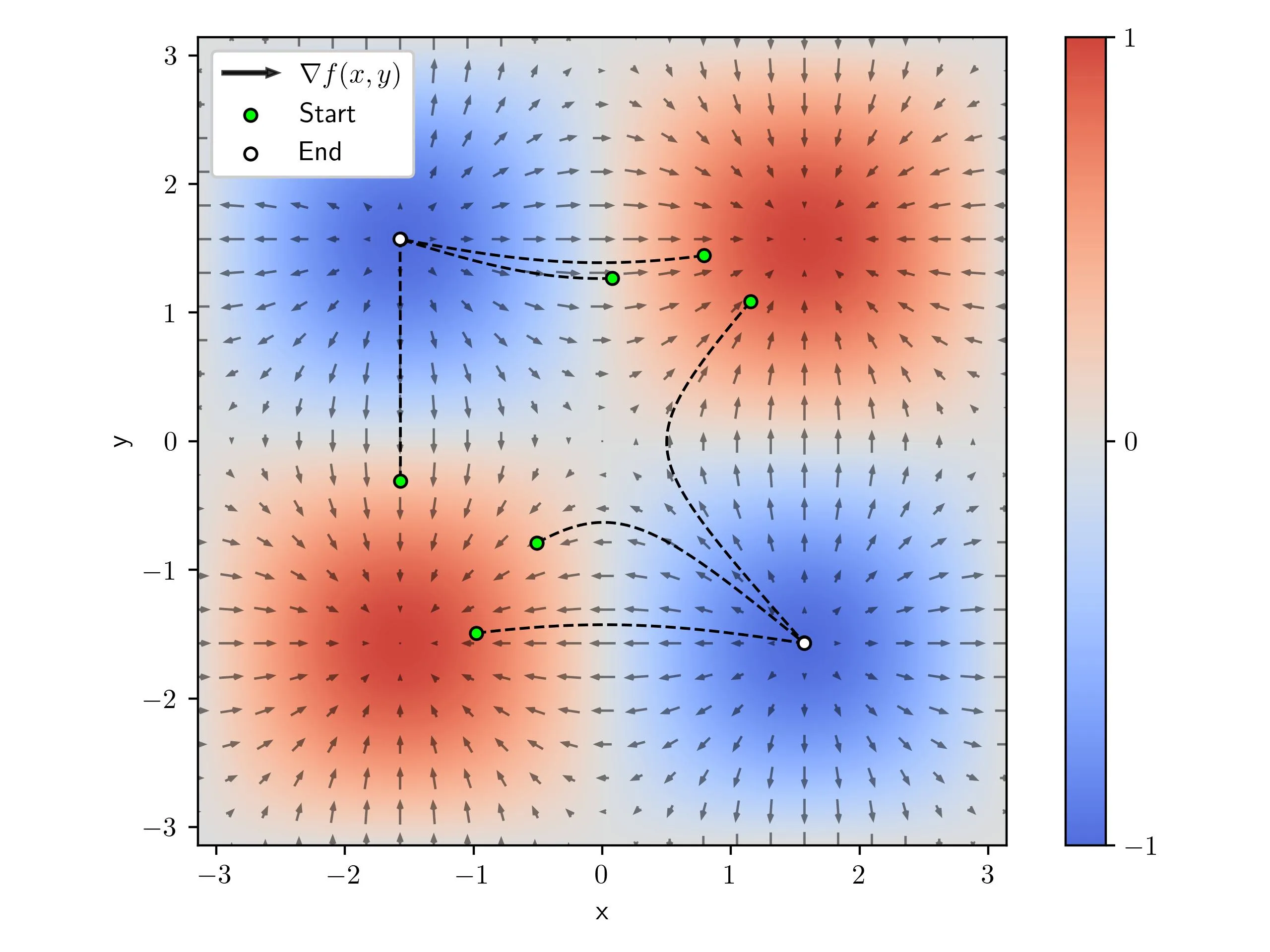
Gradient Playground
Linear Regression
Now that we have the foundations, let’s implement gradient descent for linear regression and analyze some of the behavior. In this section I focus more on the conceptual side of this problem and not the code but you can see how I implemented it in the next section.
Problem Statement
The linear regression problem is to determine the line that best fits a set of data. To be precise, let’s define some of the components of this.
Dataset
We need the inputs and the corresponding results . contains all of the samples in our dataset. An entry as a particular sample out of our whole dataset with it’s corresponding . The number of samples in our dataset is denoted as .
Model
The general model, as expected, is a simple linear model that takes in the input variables and computes a prediction . This can be thought of as the following equation.
Where the weight is the slope of the line and the bias is the vertical offset. We’re considering the scalar case where is a single number for each example in our dataset but we could also have the case where is a vector of many inputs and as such would also be a vector. In the next post, we’ll look more into what that looks like but I want start simple.
It will help to think about this model working on a single sample at a time which implies that we index a sample out of and that only results in the prediction for that sample.
Function to Minimize
We want to formulate a function that by minimizing we’ll achieve the expected behavior. One way to think about this is we want a function that indicates how bad we are doing and we want to minimize this “badness”. This is commonly referred to as a loss function.
For linear regression, we’re looking to produce a real-valued number and compare it to the dataset samples. The loss function used for this is called the mean-squared error loss (MSE).
To be consistent with our prior labeling we’ll call MSE our loss . We sub in our prior model for predicting to get the loss in terms of our model parameters and . This is because we can think of and as our knobs that we can tweak to change where the line is!
As we are trying to minimize the loss using gradient descent, we need to compute the needed gradients for our model parameters and which are the following. If you want to see step by step how I computed these partials look at the aside below.
With these gradients, we can execute gradient descent by updating our model parameters by their associated gradients evaluated at each iteration.
Linear Dataset Example
Let’s actually step into an example where we can see how the model trains and eventually performs. We’ll start with modeling a dataset where the underlying trend of the data is linear so we would expect this model to perform well.
Linear Dataset
We start with a line with a known and , in this case and , and we apply noise to the points just as we would expect real data to have. The noise is merely sampling from a normal distribution . In a real example, we would not know what the true line is and we use linear regression to estimate and of that line.
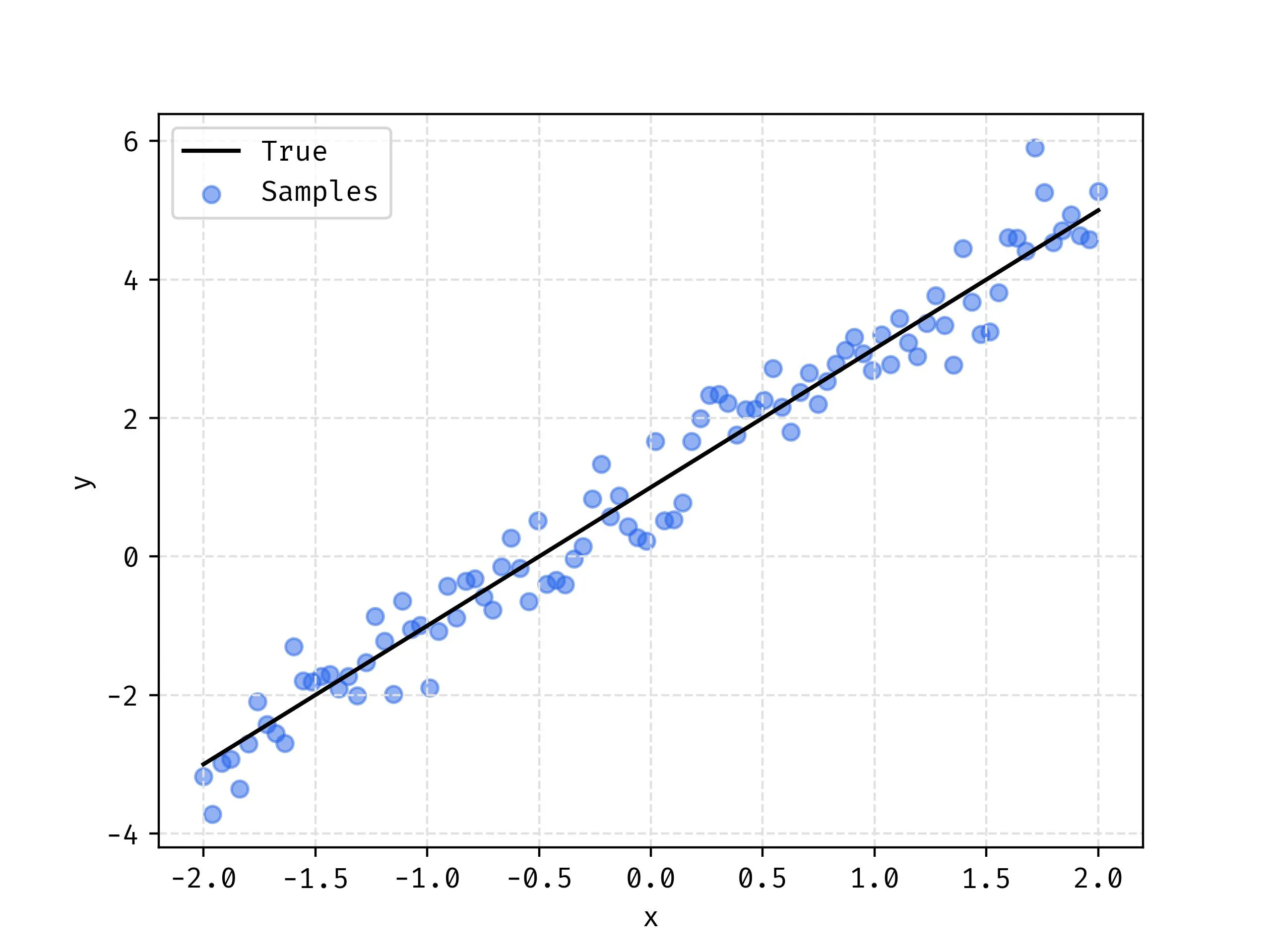
We can now execute a linear regression to solve for and and see how well we match our known true line based on fitting to the samples alone.
Training Visualization
What you can see in the video below is the loss landscape on the left and the history of our values as the point traveling through it. On the right you can see the predicted line in red plotting the corresponding line for that based on the position in the descent.
One way to think about this is that the position of the point defines a line that will have a corresponding height that is the current loss. By traversing down the loss landscape we find the such that the corresponding loss in minimal.
Parabolic Dataset Example
Let’s consider a different example where the underlying trend of the data is a parabola.
Parabolic Dataset
In the same way that we created the linear data, we will sample points along the function and apply noise to each of the points from a normal distribution.
Training Visualization
The visualization here is similar to the prior but just with the parabolic data. As we can see the method is working quite well as we’ve reached the minimum loss again.
Comparing Losses
You may have noticed that both examples reach the minimum which would indicate that we should have reached a point where the model performs well, right?
Not quite, in fact there is a concept called the bias/variance tradeoff. The general idea of this is that there are two extremes that result in poor performance.
- High Bias: The model is too inflexible to model the data correctly
- Models is too simple to adequately capture the patterns in the data
- This is where we are, there is no world where a line will correctly fit a parabola
- High Variance: The model is too flexible to generalize the data correctly
- Model is too complex and starts fitting to patterns that aren’t “real”
- Issue where the model fits to noise and doesn’t generalize the data well
Somewhere in the middle there is a goldilocks region where the model is flexible enough to encompass the complexity of the data but not so flexible that it starts overfitting.
So when we compare slices along the minimums of the loss landscapes we see that sure we may have reached the minimum but that minimum is very high for the parabolic case!
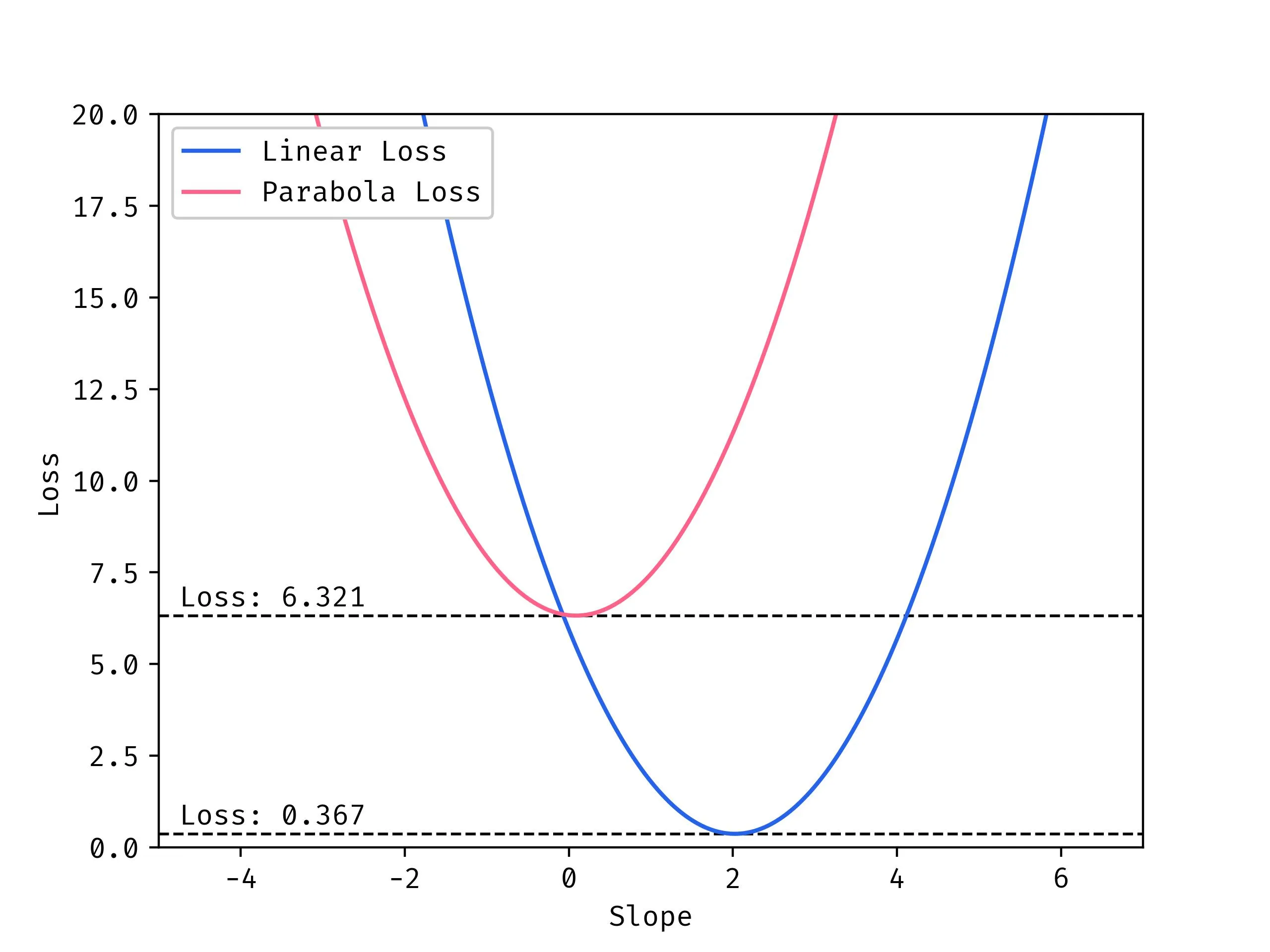
Learning Rate Tuning
The learning rate is generally regarded as how big of a step to take in the direction of the gradient during descent. Changing the value of the learning rate has massive implications on the descent time and results. Let’s consider some example and try to understand how to pick an adequate value for the learning rate.
Comparing Learning Rates
Let’s consider the convex function below where we know the optimal value lies at . With different learning rates we will see how the behavior and results change!
Across the following examples, the number of iterations is kept the same as to easily compare their behaviors but you could always adjust this when solving a problem.
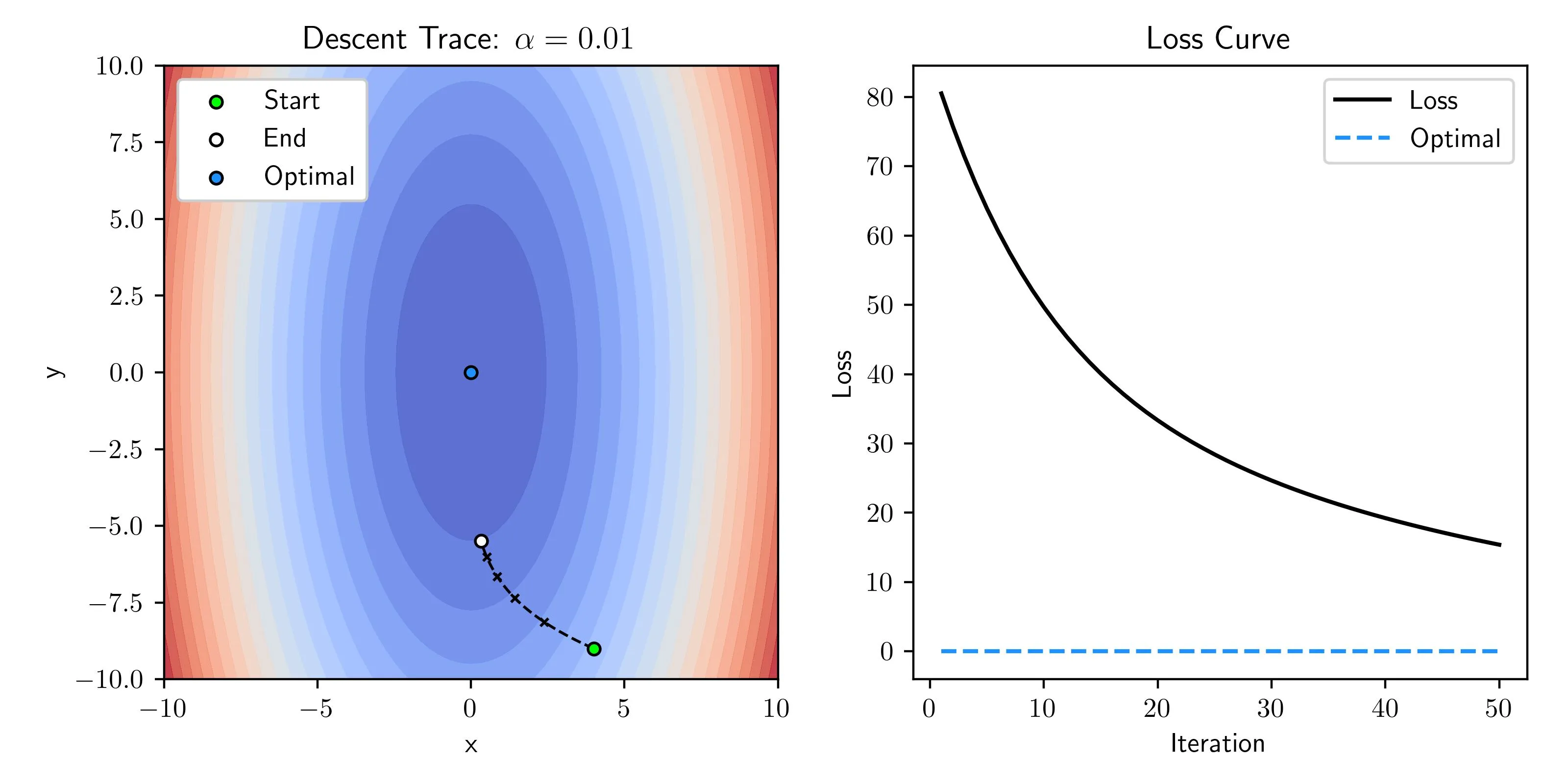
Small Learning Rate
When the learning rate is too small there isn’t a concern of instability but getting to a minima takes forever! This is not a big deal for small problems but on large problems where the computation is not trivial wasting time taking micro steps is not recommended.
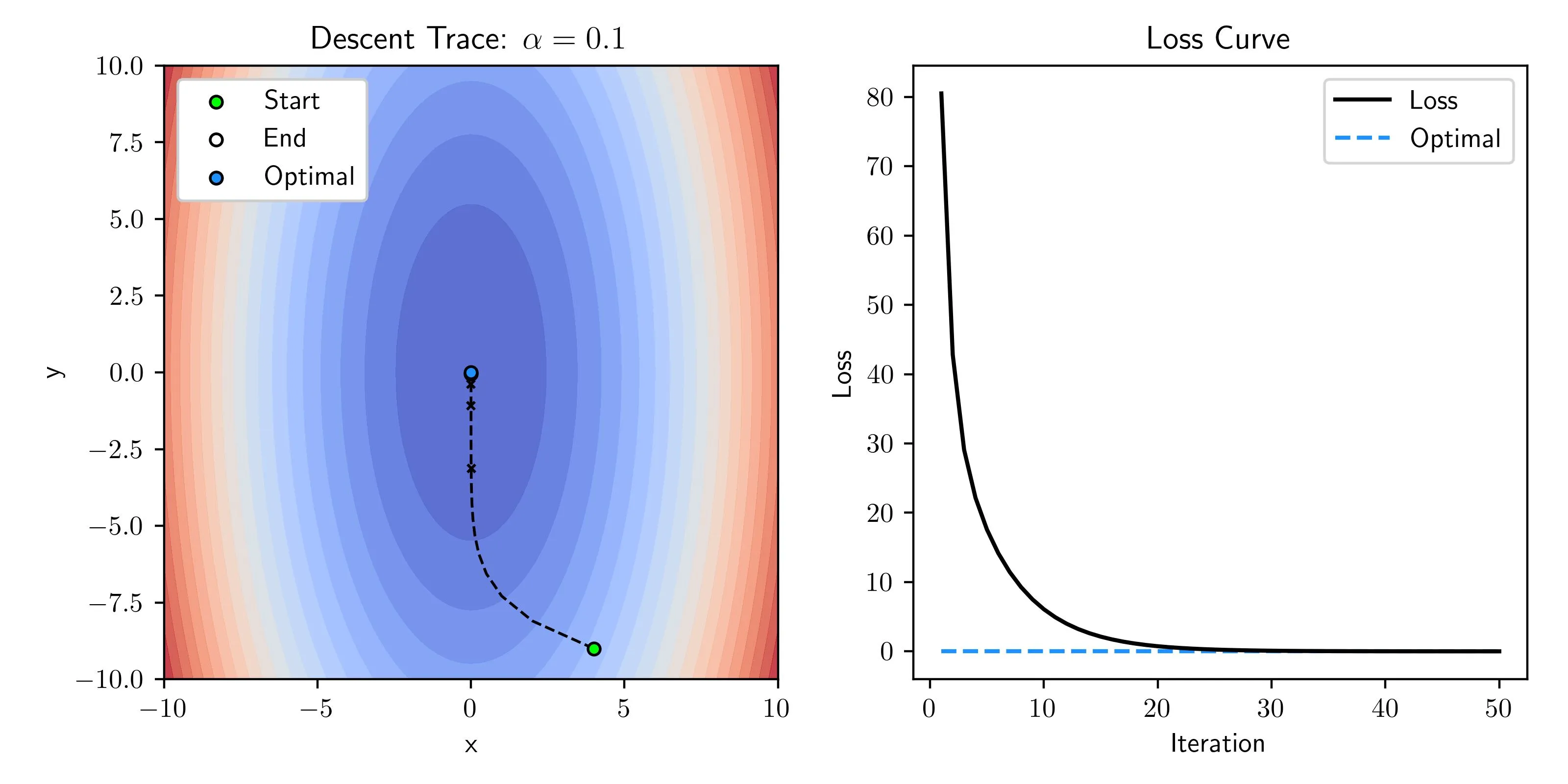
Good Learning Rate
When the learning rate is well chosen we swiftly converge to the minima without any oscillations or sporadic behavior while reaching the optimal point on our loss surface.
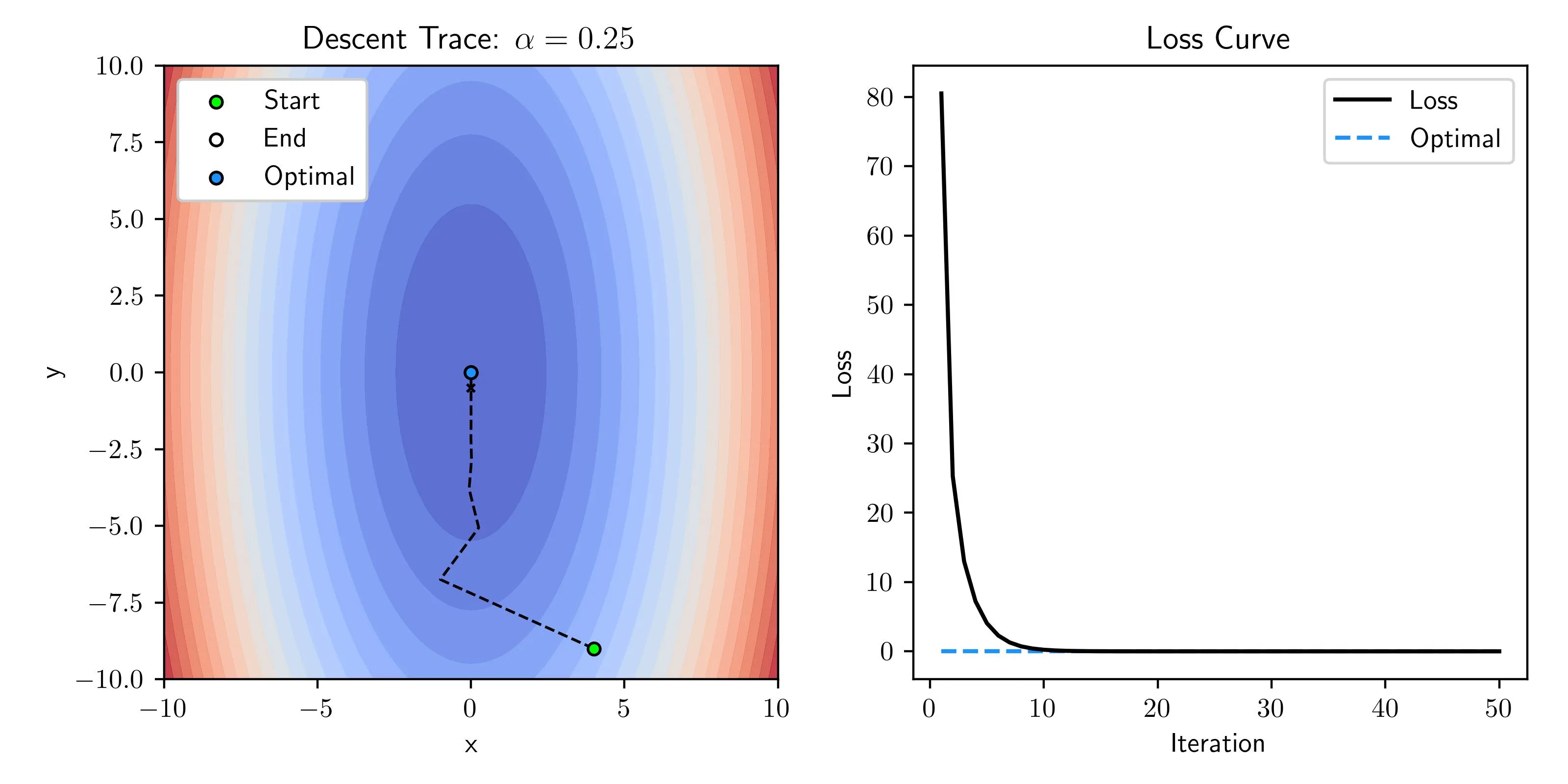
Large Learning Rate
When the learning rate is a bit large we see some oscillations as the descent settles. Looking at the loss curve everything seems perfectly fine, but one issue is sometimes you’ll see a rapid decay of loss at first and then unstable behavior as you settle in closer.
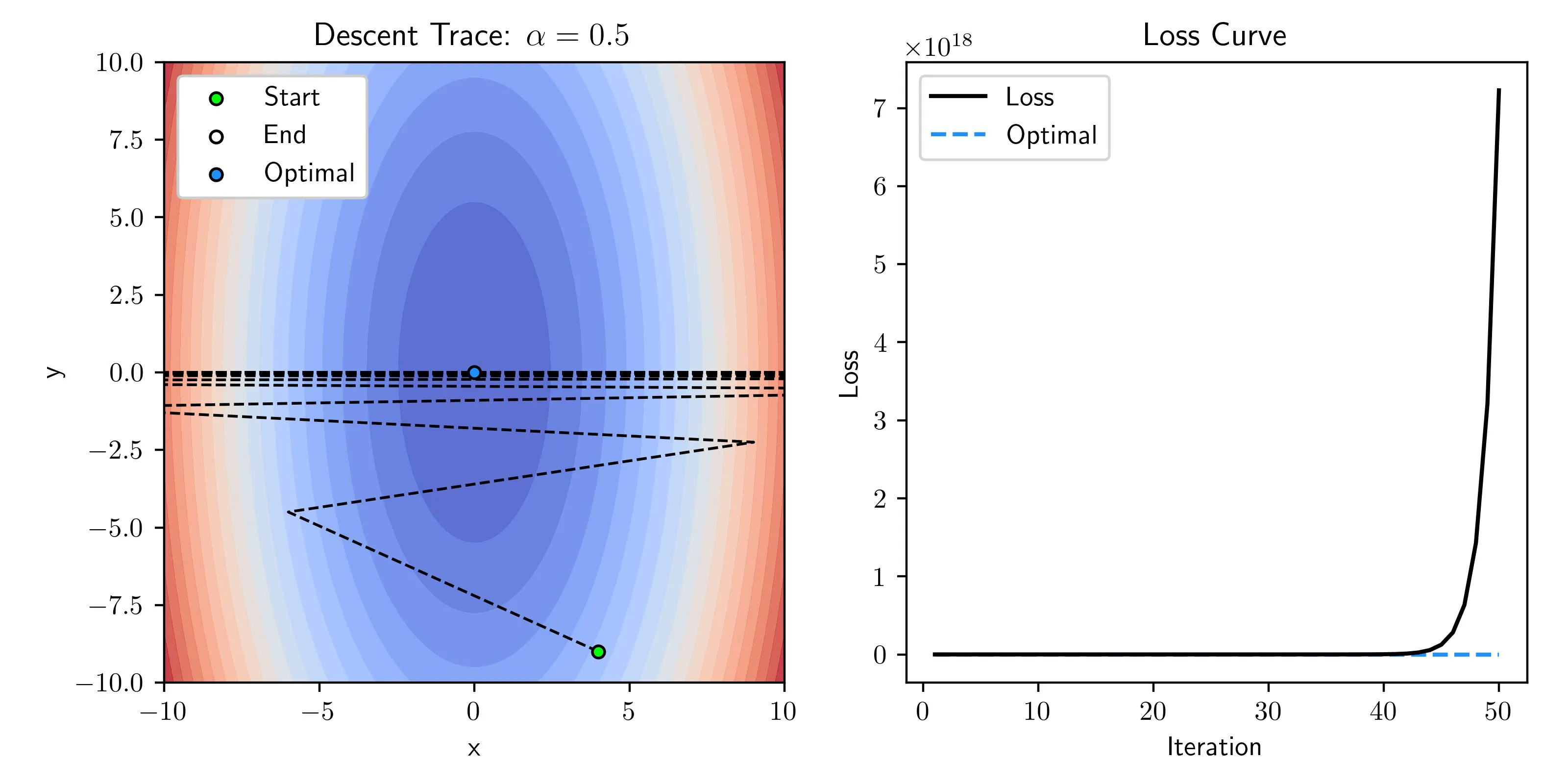
Unstable Learning Rate
When the learning rate is way too large we have unmanageable oscillations and in fact instead of converging on the optimal it diverges out to a massive loss (loss scale is 10^18)!
Where to Start
How do you pick the right learning rate? In practice, this is harder said then done and is a bit of an art. Look at similar models trained and what people used as a baseline but have fun experimenting with it too. Keep the behaviors in mind and change as you see necessary.
With better optimizers like aforementioned Adam optimizer much of these issues are handled automatically but it still helps to know general behaviors in plain gradient descent.
Extending to More Variables
As I alluded to before we can scale this model to work over many input variables where the input does not just have a scalar for each entry but instead of vector of multiple features that describe that sample. In the next post, we build off this model and extend this into many variables and show how to execute this efficiently.
Implementation
If you want to replicate this, I break down some of the code I used for linear regression here. I really wanted to focus on the conceptual understanding in this post so I pushed this to the end to focus on the process more than the code.
Necessary Imports
Just importing the libraries that we intend to use for this example.
import numpy as np
import matplotlib.pyplot as pltCreating Data
Here we create the data based on a line and add noise, if you wanted to try a different function you could add another function to represent your model but make sure to keep line_func for linear regression predictions!
# We'll use this function to generate predictions
def line_func(x, w, b):
return w * x + b
n = 100 # Number of points
X = np.linspace(-2, 2, n) # Many points between [-2,2]
Y = line_func(X, 2, 1) # Generate baseline Ys
N = np.random.normal(0, 0.5, n) # Noise to be added
S = Y + N # Add noise to create samples
# Plot Data
plt.plot(X, Y, label="True", color='black')
plt.scatter(X, S, label="Samples", alpha=0.5)
plt.xlabel("x")
plt.ylabel("y")
plt.legend()
plt.grid()
plt.show()Loss and Gradient
Here we define the function to compute our mean-squared error loss as well as getting the gradients from the input data , the true results and the predictions .
def MSE(Y, Yhat):
return np.sum(np.square(Y-Yhat)) / Y.size
def get_gradient(X, Y, Yhat):
# Get N
N = X.size
# Reused so calculating once
error = Y - Yhat
# Get gradients
dm = -2 * np.sum(X * error) / N
db = -2 * np.sum(error) / N
return dm, dbExample Gradient Descent
Here we just implement the iterative gradient descent that we’ve been talking about and print out the loss so we can see if it all works. At this point if you run the code you would expect something like the output on the code block.
iterations = 100 # Total number of iterations alpha = 0.015 # Alpha, often called learning rate model = [np.random.uniform(), np.random.uniform()] # Starting random w and b N = X.size # Number of samples for i in range(iterations): # Predict with current model params Yhat = line_func(X, *model) # Compute Loss loss = MSE(S, Yhat) if i % 10 == 0: # Every 10 iterations print print(f"Loss at iteration {i:3}: {loss:0.3f}") # Get Gradient dm, db = get_gradient(X, S, Yhat) # Update w and b model[0] -= alpha * dm model[1] -= alpha * db
outputLoss at iteration 0: 2.997 Loss at iteration 10: 1.483 Loss at iteration 20: 0.824 Loss at iteration 30: 0.537 Loss at iteration 40: 0.412 Loss at iteration 50: 0.358 Loss at iteration 60: 0.334 Loss at iteration 70: 0.323 Loss at iteration 80: 0.319 Loss at iteration 90: 0.317
Plotting Results
As a check we can plot the results and see what we get!
plt.plot(X, Y, label="True", color='black', linestyle='dashed')
plt.scatter(X, S, label="Samples", alpha=0.5)
plt.plot(X, line_func(X, *model), label="Predicted Line", color='red')
plt.xlabel("x")
plt.ylabel("y")
plt.legend()
plt.grid()
plt.show()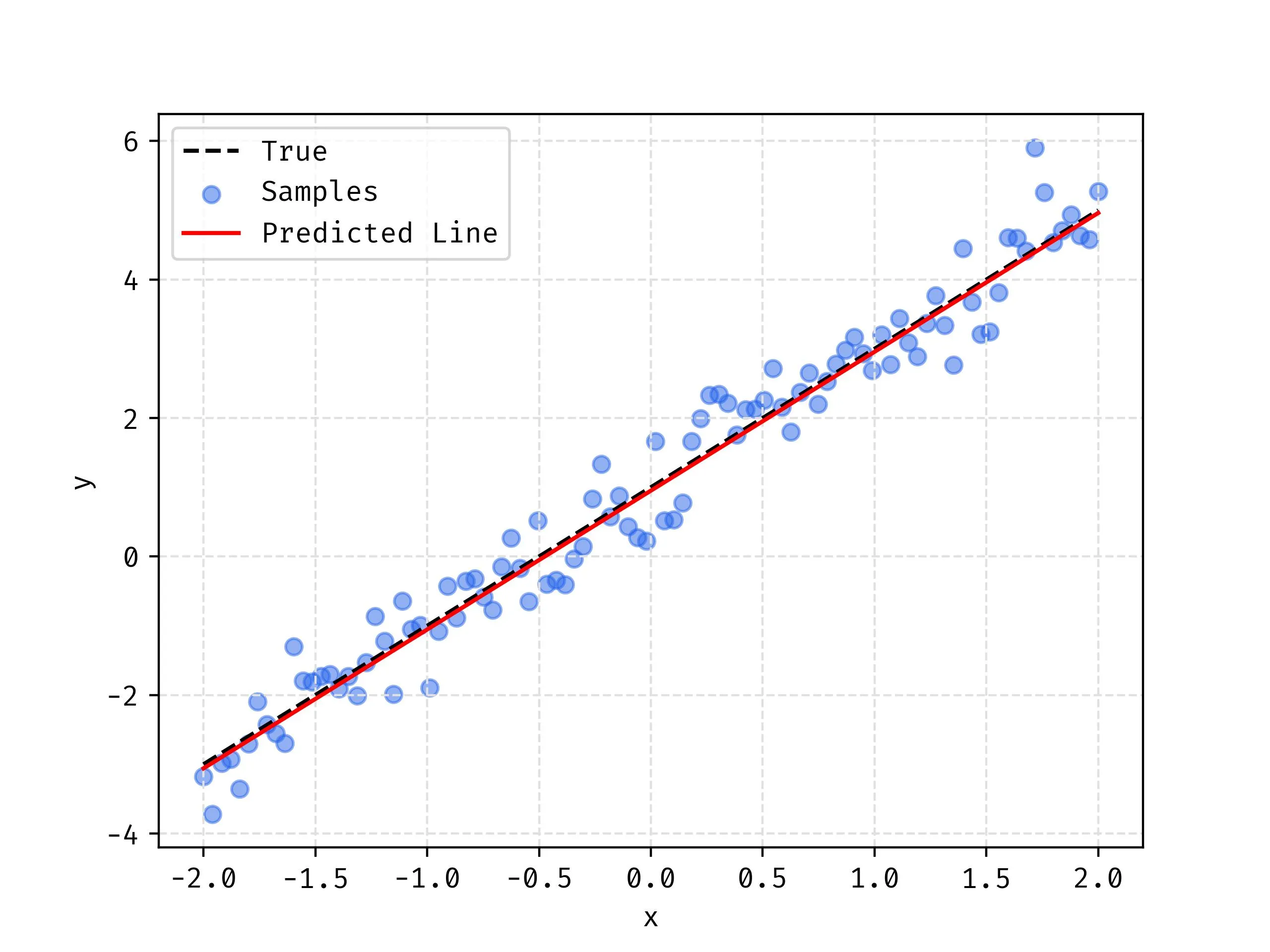
Additional Resources
As with anything, I learned this method through applying it but also external resources. I wanted to highlight a few that have helped me and might help you!
- 3Blue1Brown
- Math educator who essentially started a new genre of how math is taught, amazing!
- Cyril Stachniss
- Generally a great producer of robotics lectures.
- Math for Machine Learning
- Freely available textbooks that is a great reference for purposeful mathematics!
Closing
I hope you enjoyed this primer to the series, much of the material for the remaining posts is still up in the air so if there are aspects you liked or maybe didn’t like let me know!
