This post will introduce you to the principles behind logistic regression as a binary classification method. Using NumPy we’ll implement the model from scratch.
There are different ways to implement this particular algorithm but I will focus on an implementation with a neural network mindset.
What is Logistic Regression?
Logistic regression is a predictor borrowed from statistics used for binary classification. In english this means that we can use the model to determine is an input example belongs to a group or not. As an example, if we knew certain features about the weather (temperature, humidity, wind, etc.) we could try to predict if it’s going to rain or not. To do so, we need many labeled examples (inputs + did it rain) of data from other days.
Data Organization
We represent a particular example as a vector of features and we store all these examples as one large matrix where is a particular example (a single day if we follow our prior rain metaphor). The labeled aspect means that we know whether or not that day had rain, we’ll call this the ground-truth and save all labels for our examples in a vector where we store a 0 for the days it didn’t rain and a 1 when it does rain.
As an example, let’s imagine that we track 2 different aspects to describe each day such as average temperature and humidity. For a year, we would have 365 examples of temperature and humidity stored in our vector and the rain history in our vector .
Forward Propagation
The forward propagation step is where we take an example day and pass it through our model to yield a prediction . We need a signal of how important each of the input signals is to whether it rained and in which direction it pushes our guess.
The importance as I called it is more aptly called the weight, we store a weight value for each of our input values (humidity and temperature). A positive weight implies that an increase in the input signal corresponds to a higher likelihood of predicting true. Across all our possible inputs, it’s easier to combine all the weights into one vector .
We may need to shift our baseline as well, to do this we include an offset that in a way sets our start for where we start allowing our inputs to change off of, called the bias .
Lastly, we need a way of “squashing” the signal down to yes and no. This is best done as a probability where 0 says definetely not, and a 1 is very confident. We want to take the loudest of voice, and quietest of whispers and clamp them to a range we actually know how to handle. This is done with the sigmoid function .
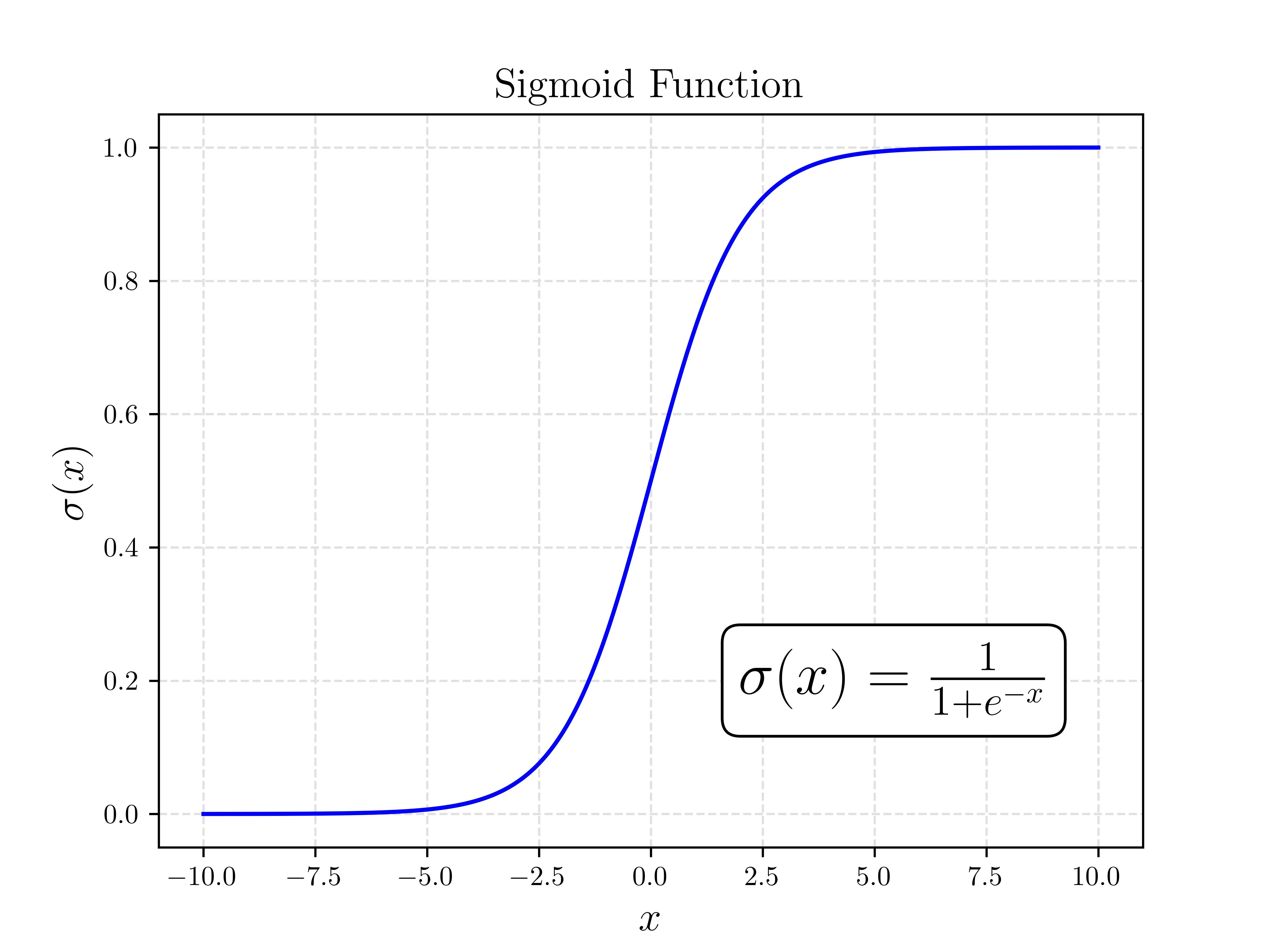
Where is the probability that the example is in the class we are trying to predict. For the rain example, this is the logistic regressions estimated probability that it will rain that day. The sigmoid function is well catered to this as it introduces a non-linearity that bounds the output between 0 and 1, perfect for a probability!
Example Forward Propagation
Let’s consider our example in the prior data organization section. I understand that at this point I have not discussed how to determine and but for now follow that we know it, we will discuss how to find the correct values in the next section. Let’s use the following:
We can actually go ahead and bulk propagate all examples using matrix multiplication! Let’s use and as the define days from before. What we’re looking at here are 4 days worth of information with their respective humidities and temperatures.
We can see in the corresponding that it rained on days 2 and 3.
Following the equation for we get the following:
When we compare those probabilities to the known results we can see they match! Days that had rain (days 2 and 3) show high probabilities that it rained and the non rain days respectively show low probabilities. In practice you can get a prediction as a 1 or 0 by rounding the probability, the idea is you round towards the prediction that is more likely in the probability. In the case of logistic regression where there are only two possibilities (rain or didn’t) you can estimate one from the other very easily.
Bias Simplification
A trick I’ve seen is to move the bias term () into the matrix multiplication ().
This is done by adding a column of 1’s to the end of , adding a feature that is consistent across all examples. Then we increase the size of the weights by 1 (now etc.) such that the last weight acts as the bias. Check the math below if you are still curious.
For the sake of expanding this into greater content and not making reductions that are specific to this problem, I will opt to not do this but thought I’d mention it.
Finding the Correct and
It can be difficult/impossible to determine the correct values for the weights and bias through trial and error. Even for small examples of only two input features it’s challenging to get correct, let alone when we step into many more.
To correctly determine the values we use a process called training!
Training
Training is the process where we take many labeled examples and use them to determine values for that will yield us the best overall performance. To be precise, we will describe some formulations for what are called the cost and loss of the model.
Loss Function
Let’s start with the loss function. The loss is a measure of the error for a particular example’s prediction. Following our prior notation the loss for one example is:
This function evaluates the error differently depending on the true label . Let’s play this out and see why it makes sense.
Case 1: It Rained
When the actual outcome is rain (), the loss simplifies to:
An ideal prediction would have , resulting in:
Predicting any probability lower than 1 (less certain of rain) increases the loss.
Case 2: It Did Not Rain
When there’s no rain (), the loss becomes:
Here, the ideal prediction is , yielding:
Predicting higher probabilities incorrectly indicating rain increases the loss significantly.
Intuition
The logistic regression loss function quantifies prediction errors for both outcomes ( or ), penalizing predictions increasingly as they diverge from the observed reality.
Cost Function
The cost function is easy, it’s just the average of the loss functions so:
The cost gives us an idea of how we are doing overall against all of our data.
We want to find a way to reduce this to the lowest value possible. To do so, we use an optimization method called gradient descent.
Gradient Descent
This method isn’t the focus of the post, so if this feels bit heavy don’t worry too much. I introduce this as the method of choice because neural networks also use it so it’s good to get exposure to it here!
Gradient descent is fairly simple, given the gradient of a function with respect to the variable to be optimized take a step in the negative direction of the gradient (positive for gradient ascent) and update your inputs with the step. Keep repeating this until you are happy with the convergence. In general, it looks something like this:
Where is a tuneable parameter called the learning rate, it dictates how fast or slow we should update our parameters relative to the gradient. I will not go through the derivation, but for our problem we would like to use gradient descent where is the cost function and we take the gradient in terms of and . For our use case this is:
Implementation
Let’s go ahead and import our python modules first as follow:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import StandardScalerI will be using Python/NumPy for the implementation. The dataset used is imported in our prior code block with the rest of our libraries. The dataset takes a few human health metrics as features and tries to predict if the patient has breast cancer, you can read more here.
Model Class
We’ll package this a class just to keep everything together.
class LogisticRegression:
def sigmoid(self, z):
pass
def cost(self, y, y_hat):
pass
def train(self, X, y):
pass
def predict_prob(self, X):
pass
def predict(self, X):
passsigmoidwill be our implementation of the aforementioned non linear functioncostwill be used to compute the cost across a set of many predictionstrainwill take the training input and the corresponding outputspredict_probwill return the predicted probabilities from the model weightspredictwill use the probability to return a class decision
Populating all the methods and __init__ yields the following:
class LogisticRegression:
def __init__(self, learning_rate=0.01, epochs=1000):
self.learning_rate = learning_rate
self.epochs = epochs
def sigmoid(self, z):
return 1 / (1 + np.exp(-z))
def cost(self, y, y_hat):
loss = -y * np.log(y_hat) - (1-y) * np.log(1-y_hat)
return np.average(loss)
def train(self, X, y):
# Initialize Weights Randomly, Bias to 0
n_samples, n_features = X.shape
self.W = np.random.randn(n_features)
self.b = 0
# Gradient Descent
for i in range(self.epochs):
# Get Probabilities
y_predicted = self.predict_prob(X)
# Compute Gradients
diff = y_predicted - y
dW = (1 / n_samples) * np.dot(X.T, diff)
db = (1 / n_samples) * np.sum(diff)
# Update Model Parameters
self.W -= self.learning_rate * dW
self.b -= self.learning_rate * db
def predict_prob(self, X):
linear_model = np.dot(X, self.W) + self.b
return self.sigmoid(linear_model)
def predict(self, X):
y_predicted_prob = self.predict_prob(X)
return np.round(y_predicted_prob)With the dataset and prep methods we imported prior we can fashion a test. It’s customary to split the data into a test/train split where we train on a larger fraction of the data, and then test our performance on an unseen part of the dataset to see how well the model generalizes.
# Load in data data = load_breast_cancer(return_X_y=True) # Split into X and y X = data[0] y = data[1] # Test Train Split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.40, random_state=12) # Standardize Input Data scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) # Instantiate Model and Train MyModel = LogisticRegression(0.2, 2500) MyModel.train(X_train, y_train) y_train_pred = MyModel.predict(X_train) train_accuracy = np.sum(y_train_pred == y_train) / y_train_pred.size y_test_pred = MyModel.predict(X_test) test_accuracy = np.sum(y_test_pred == y_test) / y_test_pred.size print(f"Accuracy on train: {train_accuracy:0.3f}") print(f"Accuracy on test: {test_accuracy:0.3f}")
outputAccuracy on train: 0.997 Accuracy on test: 0.969
Overfitting
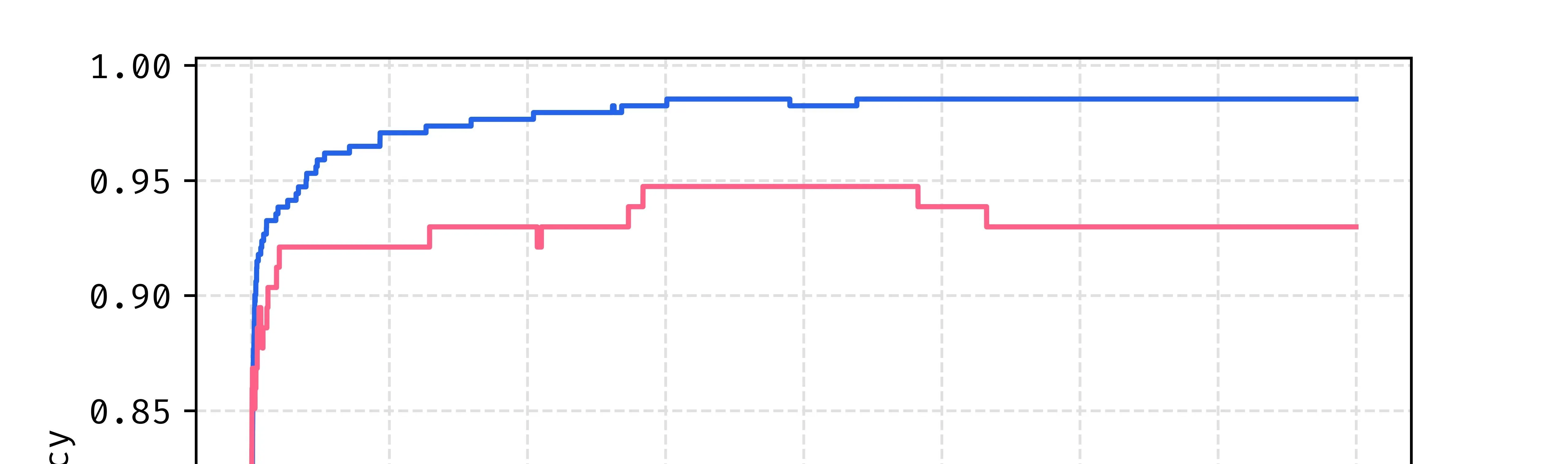
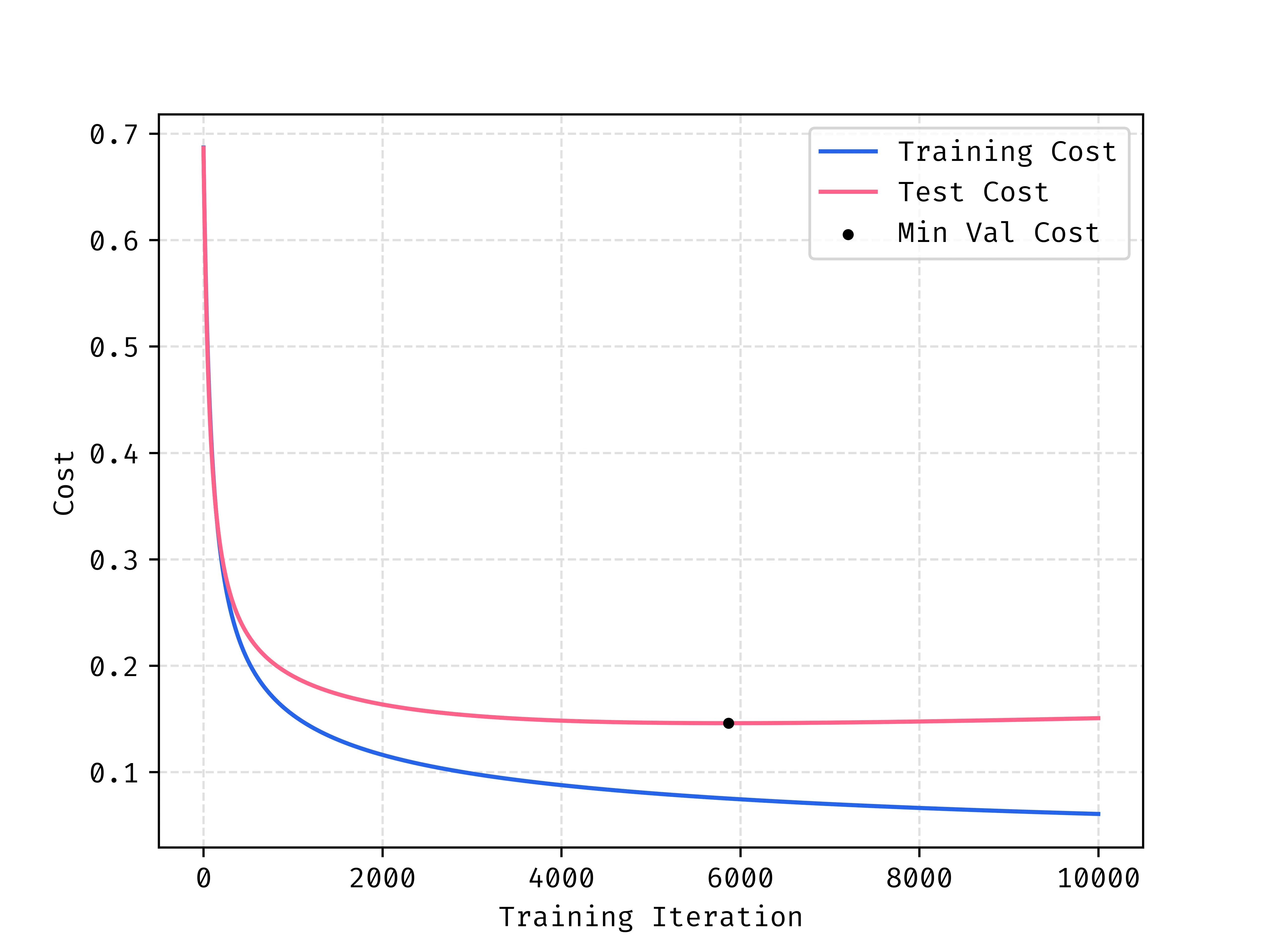
A problem that we see in machine learning a lot called overfitting. The model only sees the training data set, and with a sufficiently large model and enough training the model can learn to match the input training data too well. When this happen, the performance of the model on the unseen or “test” data regresses, so we want to stop earlier than this stage.
When looking at the costs of both the training and test data during training we see that the minimum cost for test data happens well before the end of training. Past this point the model is overfitting to the training data so we see that cost reducing, but this provides no value to us because the test and unseen data in the future is ALL that matters.
This is also reflected in the accuracy at roughly the same place in the training stage.
Conclusion
Logistic regression may be simple, but it’s a powerful gateway into the world of classification and machine learning in general. By walking through its mathematical intuition, implementation from scratch, and interpretation, we’ve laid the groundwork for understanding more advanced models like neural networks in future posts.
Thanks for reading, hope it sparked something!